Building a CI/CD Pipeline for Private GKE Clusters with Google Cloud Deploy
Building a scalable CI/CD pipeline for private GKE clusters using Google Cloud Deploy, with streamlined integration, environment management, and observability.
A robust Continuous Integration and Continuous Delivery (CICD) pipeline plays a crucial role in any development ecosystem, introducing dependability, efficiency, and adaptability to your integration and delivery workflows. As part of our company's ongoing re-architectural efforts, we recently engineered a CICD pipeline tailored to seamlessly support the deployment of Google Kubernetes Engine (GKE) workloads. The system was designed with the following criteria in mind:
- Separate build and deployment steps
- A single control point to manage the release lifecycle
- Support workload deployment into private GKE clusters across different GCP projects. (eg: staging & production)
- Environment promotion and rollback support for releases.
- Observability
A high-level visualisation of the final architecture is shown below:
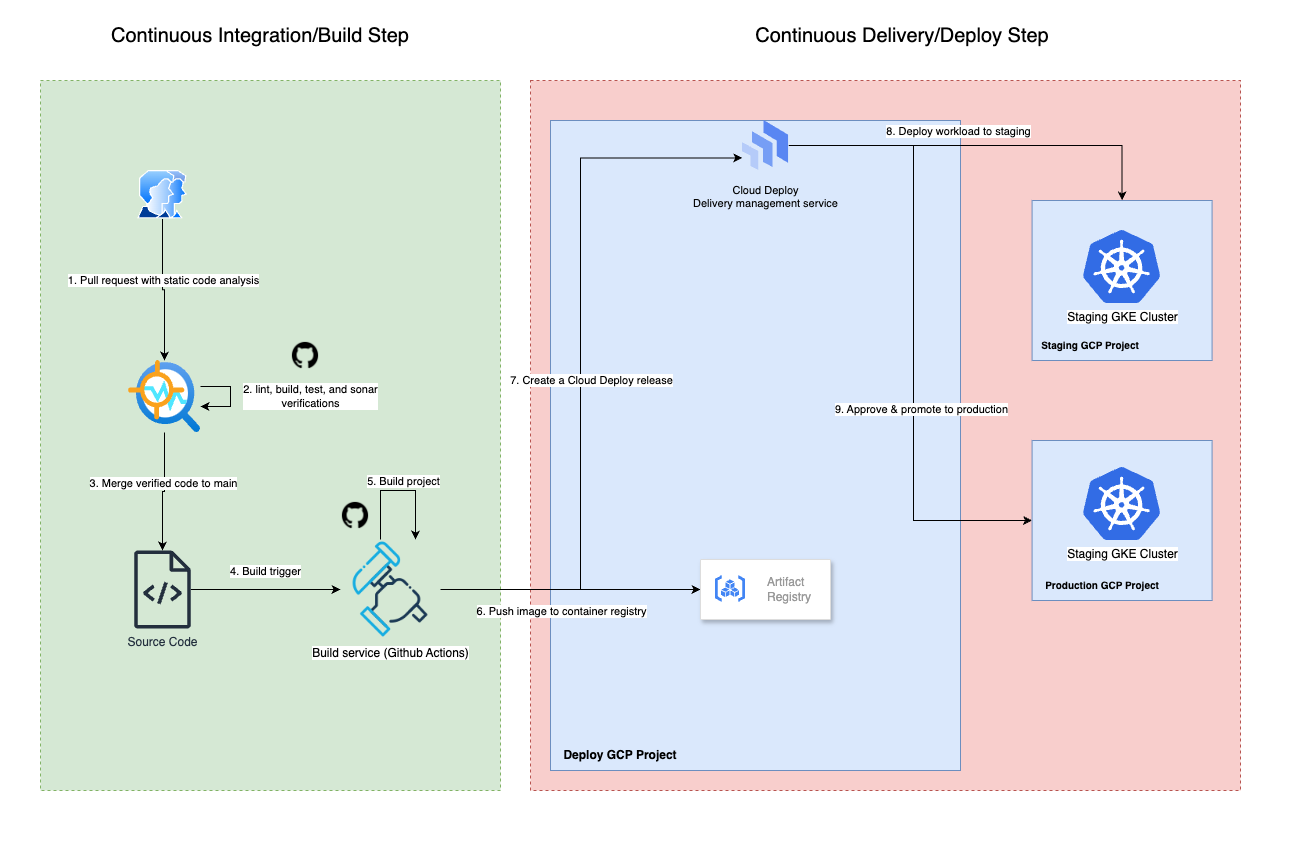
The Build Step
Github Actions is used for the build step. The build action is triggered via a successful pull request merge to the main branch. The action runs code verification and initiates the docker build. On completion, the built artifact is pushed to the Google Artifact Registry.
The build step will also call the Google Cloud Deploy service to create a release for application deployment. We will look into the details of this process in the next section.
Authentication for GCP from Github Actions is handled via OpenID Connect (OIDC) with Google's Workload Identity Federation. This approach allows workflows to get temporary access tokens when needed, while eliminating the overhead and risk of managing sensitive service account keys.
The Deploy Step
The CD system is orchestrated through a separate GCP project, independent of the staging and production GCP projects using Google Cloud Deploy. Cloud Deploy is a Google-managed service that automates delivery and allows you to manage the release lifecycle of your applications. It interacts with the following systems:
- CI - As mentioned in the previous section, the CI system (Github Actions in our case) is required to create a release on Cloud Deploy as a final step of the CI process. This effectively initiates the CD process.
- Cloud Build Worker Pools - This is the execution environment for Cloud Deploy, through which a release is deployed to a target runtime (eg: GKE cluster). Cloud Deploy supports a default worker pool as well as private worker pools. The former is sufficient to manage deployments into public GKE clusters, however for more advanced use cases (eg: private GKE clusters), private worker pools are required.
- Skaffold - Skaffold is a CLI tool to manage declarative configuration for Kubernetes applications. This is used by the worker pool to RENDER and DEPLOY the Kubernetes manifest files.
- Cloud Storage - The rendered manifest files are stored in Google Cloud Storage. This mainly includes declarative configuration describing the deployment.
RENDER involves the worker pool processing the Skaffold configuration to generate the Kubernetes manifests, while DEPLOY is the process through which the generated manifest files are applied to the GKE cluster.
A detailed visualisation of the deploy system is shown below:
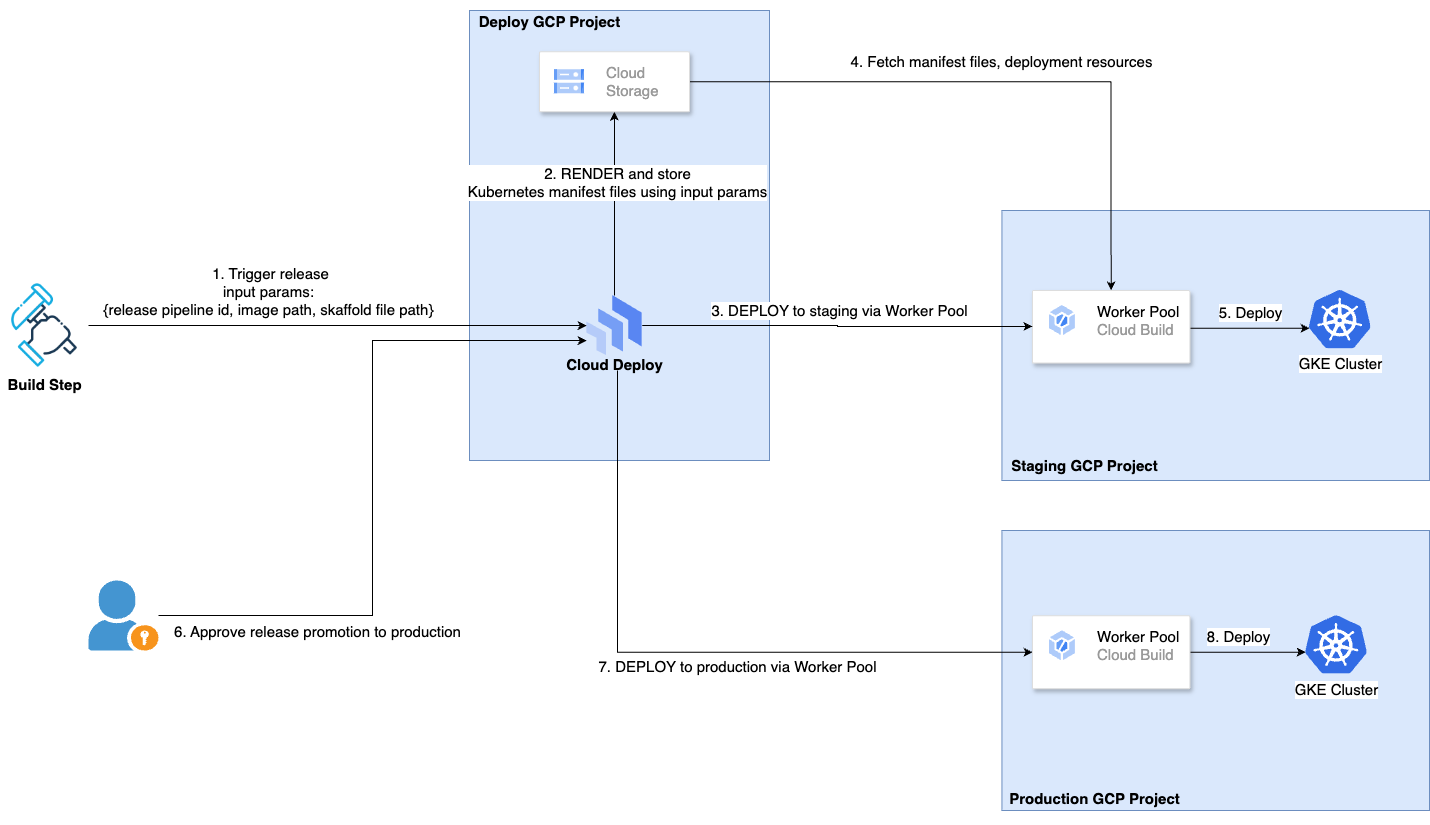
Private Worker Pools
Now that we understand the main components of the CD system, the next step is to look at how private worker pools are used to manage their respective deployments into a private GKE cluster.
An important point to note is that, although the worker pool is created in our GCP project (staging or production), the actual worker instances are running in a Google-managed VPC, and are connected to our VPC network using a VPC Network Peering connection as shown below:
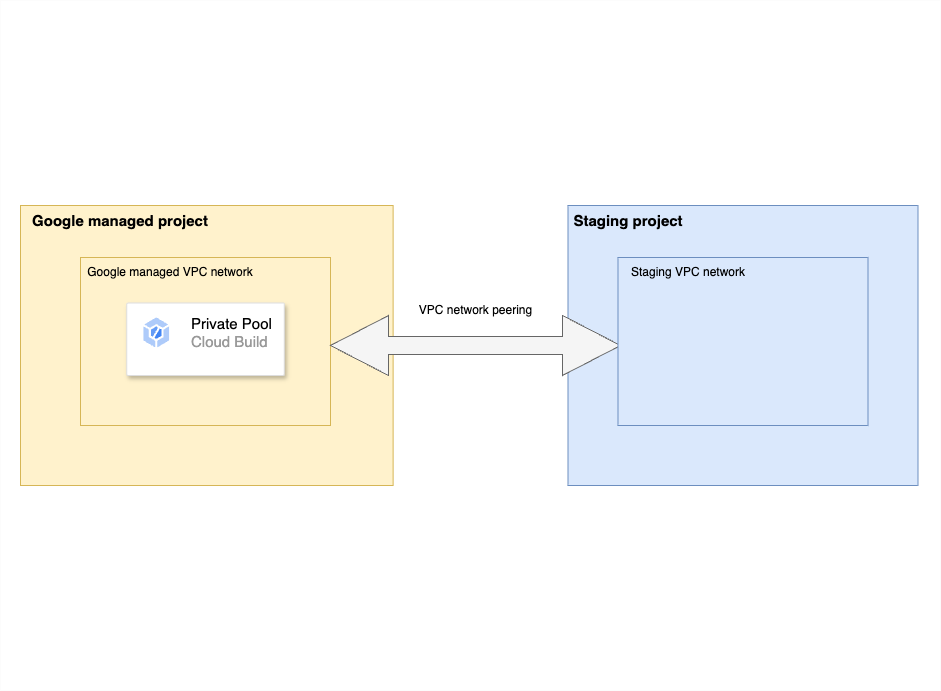
This brings us to an interesting complexity in the CD system. Since the worker pool needs access to the GKE control plane to perform the deployment (which is also running in another Google-managed VPC), and since Google VPC network peering does not support transitive peering, we have no way to establish a direct connection from the worker pool to the GKE control plane.
While assigning a public IP to the cluster control plane was an option for access, we avoided this route to uphold strict cluster security.
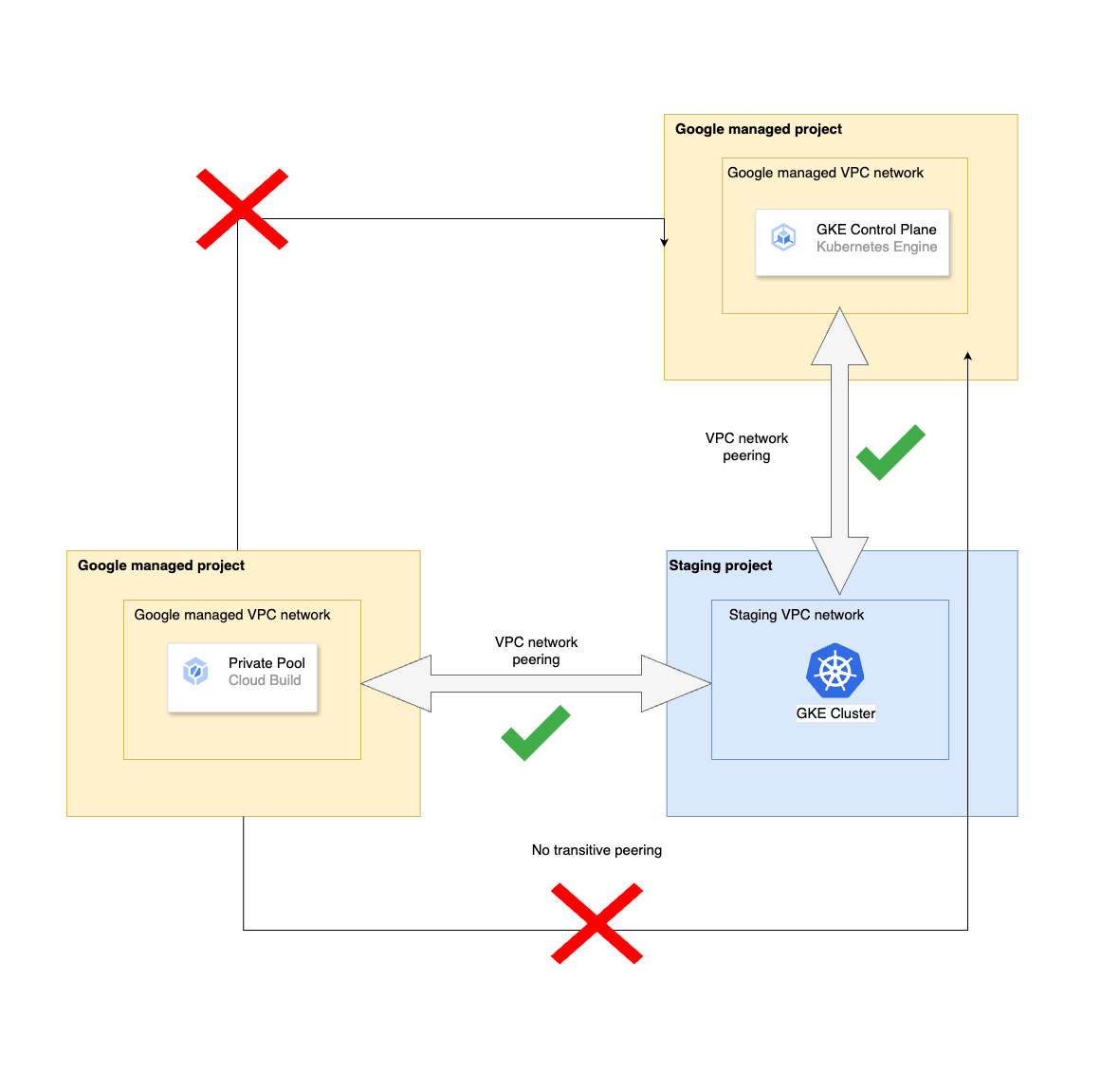
Fortunately, Google has provided a very detailed guide on tackling this very use case using two VPC networks within our project, peering each of them with the Google-managed VPC networks, and finally connecting them together using Cloud VPN. This peering and connection allows each side of the VPC tunnel to advertise the private pool and GKE cluster control plane networks, completing the route between the private pool and the GKE control plane.
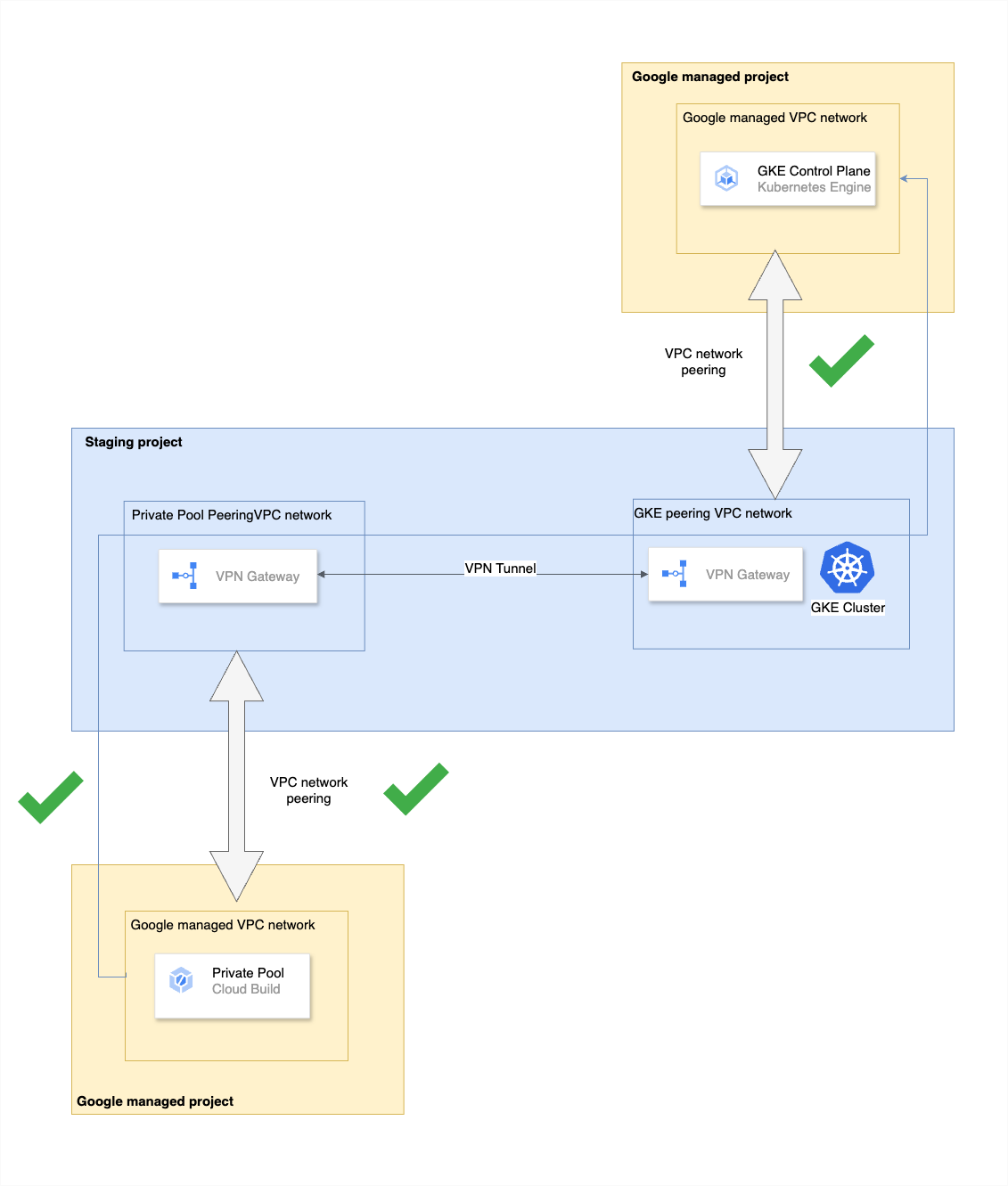
The successful completion of the above guide will ensure that you have a Cloud Build worker pool(s) capable of deploying an application workload to your target private GKE cluster.
The Delivery Pipeline
Each application workload that is to be deployed, need its own delivery pipeline set up on Cloud Deploy. The pipeline can be created via a declarative YAML definition as shown below. The provided definition has support for multiple environments and uses two separate private worker pools to deploy the application into their respective GKE cluster.
Once the YAML definition is correctly setup, the deployment pipeline can be created via CLI using the following command:
The Build Trigger
This brings us back full circle, to the CI system. If you recall, the last responsibility of the build step is to create a release to initiate the deployment step. Let's take a deeper look at what this exactly means. The code snippet below is the step in the build action that actually performs this operation.
The step uses create-cloud-deploy-release, a Github Action to create Cloud Deploy releases which consumes a few parameters of interest that makes the entire workflow possible.
It is worth checking out the Create-cloud-deploy-release documentation for additional and alternate configuration details that you may need depending on your deployment process.
- delivery_pipeline - This value should correspond to the id of the delivery pipeline that you have created for your specific application.
- skaffold_file - The path to the Skaffold definition containing details of the Kubernetes release. The Skaffold file is used by Cloud Deploy to generate the Kubernetes manifest files during the RENDER step in the CD system. Additionally, the Skaffold file supports profiles, making it easier to manage environment-specific Kubernetes configurations during deployment.
- images: This is the URL path to the docker image that was pushed during the build process.
With these parameters configured correctly, the Build Action will create the release to initiate the deployment process. From there onwards, the deployment process will progress as outlined in the previous section.
Observability & Monitoring
What is a system without observability? Fortunately Google Cloud Deploy's out of the box offerings are more than enough to cover the observability requirements of our CICD system.
Through the Cloud Deploy console, you can easily track the status of releases, monitor deployment progress, and view important metrics such as deployment duration and success rates. The console also supports rollback actions, allowing you to revert to previous releases quickly and efficiently if needed. This level of visibility ensures that you can maintain control over your deployments and respond promptly to any issues that arise.
I hope this article has provided clarity on the key architectural elements necessary for building a CI/CD pipeline for GKE using Google Cloud Deploy. By sharing our experience and the challenges we faced, we can hopefully support and help others navigate similar complexities in their own projects. Your comments, suggestions, and insights based on your experiences are certainly welcome!