Architecting a Production-Grade GKE Environment
Setting up a production-ready Google Kubernetes Engine (GKE) setup.
This article outlines important architectural elements required to establish a production-ready Google Kubernetes Engine (GKE) setup. Insights have been gathered from a recent infrastructure re-architecture project within our organisation, where an end-to-end GKE cluster setup was completed, with a strong emphasis on industry-standard design and security.
This is not an implementation guide, but rather a bird's eye view of key architectural components that you may need for a secure, production ready, GKE cluster.
Diagrammed below is a visual representation outlining the adopted GKE architecture:
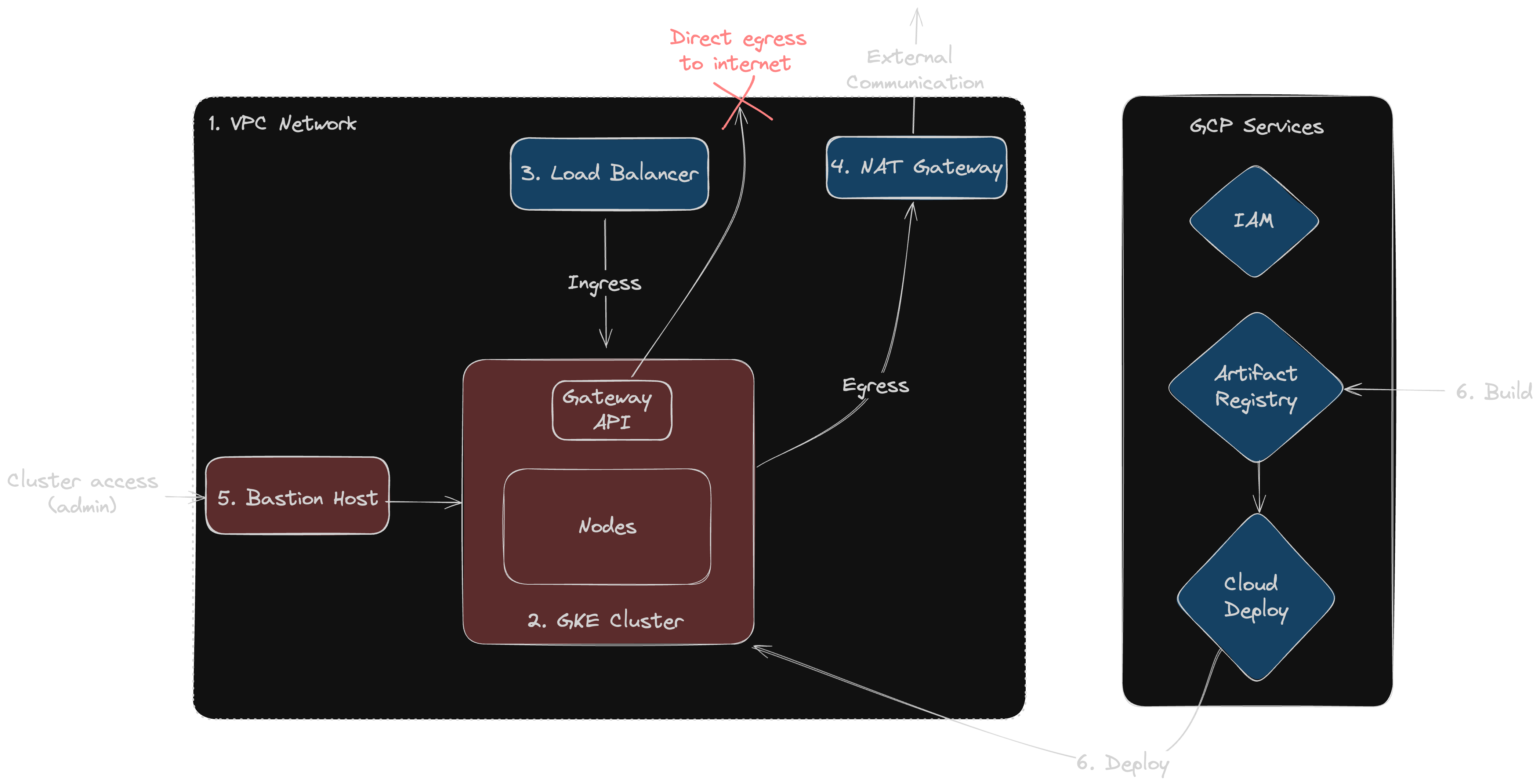
The following key areas of architectural significance were identified:
- VPC network
- GKE cluster
- Load balancer
- NAT gateway
- Bastion host
- CICD pipeline
Let's explore each aspect in more detail.
VPC Network
The Virtual Private Cloud (VPC) serves as the foundational infrastructure piece for the GKE cluster. The VPC network will provide an isolated network boundary for the cluster, securing it from the public internet.
The creation of a custom VPC network with its own IP address range (subnet) is recommended.
GKE Cluster
The GKE cluster itself can be configured using various configuration details, most of which would be based on your specific requirements. However, the following key recommendations are suitable for a production ready cluster setup.
- Ensure the cluster is private - A private cluster will assign internal IP addresses to pods and nodes within the cluster (whereas a public cluster will assign public IP addresses). This will isolate the cluster's workloads from public networks.
- Disable control plane access via public endpoints - The control plane hosts components that manage the Kubernetes cluster. Disabling control plane access via public endpoints will lock down external access to the cluster's control plane. This may result in certain accessibility complexities, but it is a worthwhile compromise to enhance cluster security.
- Enable workload identity - Workload Identity allows workloads within a GKE cluster to impersonate Identity and Access Management (IAM) service accounts. By binding a GCP service account with your GKE cluster, the cluster can gain access to Google Cloud services, without the need for explicit service account keys to be exposed within the cluster.
- Enable Cloud Monitoring & GKE usage metering - GKE seamlessly integrates with Google Cloud observability tools for monitoring. These tools can be used to monitor workload health and gain detailed usage insights and vital metrics of your GKE cluster.
Load Balancer
The load balancer will be the primary entry point that accepts and routes external traffic in to the GKE cluster. In GKE, external load balancers will be automatically configured once the cluster is configured with either an Ingress Controller or the Gateway API.
While both options are still viable, the preferred architectural choice for our infrastructure was the Kubernetes Gateway API. The Gateway API is considered as an evolution of Ingress, with improved/simplified routing, and better separation of resources.
It is also recommended to configure the load balancer with a static IP address, SSL configuration and a domain to enhance reliability, security, and accessibility. This is easily accomplished through the Kubernetes Gateway API yaml definition file.
Both the Ingress Controller and the Kubernetes Gateway API serve as Kubernetes resources responsible for managing external access to services within the cluster. In the context of GKE (Google Kubernetes Engine), which is a managed Kubernetes offering by Google Cloud, Google Cloud Load Balancers are utilised within the underlying infrastructure to enhance the functionality of Ingress Controllers or potentially the Kubernetes Gateway API, efficiently routing incoming external traffic to services within the GKE cluster. While Google Cloud Load Balancers significantly complement these Kubernetes resources, their usage is not mandatory for the core functionality of Ingress Controllers or the Kubernetes Gateway API within a GKE cluster. These resources can operate independently or in conjunction with other load balancing solutions depending on your cluster requirements.
NAT Gateway
Workloads within a private GKE cluster are exclusively accessible via internal IP addresses. As a result, these workloads are restricted from communicating with resources beyond their designated subnet boundaries.
To enable connectivity with external resources, the recommended approach involves implementing external access through a NAT (Network Address Translation) Gateway. A NAT gateway, being a regional resource, can be configured to facilitate communication for specific or all subnets within the given region.
This setup enables seamless communication between the cluster and external entities.
Bastion Host
One caveat of setting up a private GKE cluster is accessibility. As the cluster's control plane lacks a public IP address, direct external connections to the GKE cluster is not possible. This is where the concept of a bastion host comes into play.
The Bastion host refers to a designated virtual machine instance deployed within the same subnet as the GKE cluster. Its primary function is to serve as an intermediary link, possessing controlled access to both the internal network housing the GKE cluster and the public internet.
Through a combination of ssh tunneling and port forwarding, authorised users or administrators can gain remote access to the cluster's management APIs via the Bastion host. This setup enhances security by creating a controlled and monitored gateway for managing the private GKE cluster.
CICD Pipeline
A detailed rundown of the CICD pipeline architecture to support GKE workload deployments merits its own separate article. However, here are some aspects that were factored into the setup:
- Clear environment separation - The pipeline is extensible and supports multiple environments with seamless workflow management capabilities.
- Independent build & deployment steps - With a clear separation between build and deployment steps, autonomy and efficiency is maintained in the workflow.
- Build once, deploy anywhere - This is an important principle that was adopted which allows for a single build artifact to be deployed across different environments, enhancing consistency and reliability.
- Automated dev/staging deployments - The setup includes automated deployments to development and staging environments, reducing manual intervention and ensuring rapid iteration.
- Environment promotion support - Capability to seamlessly promote deployments from one environment to another, ensuring smooth progression of releases.
- Rollback support - Incorporating mechanisms to revert to previous versions or states in case of issues or errors, providing robustness and resilience in deployment.
With these considerations in mind, the following architecture was developed for the CICD workflow:
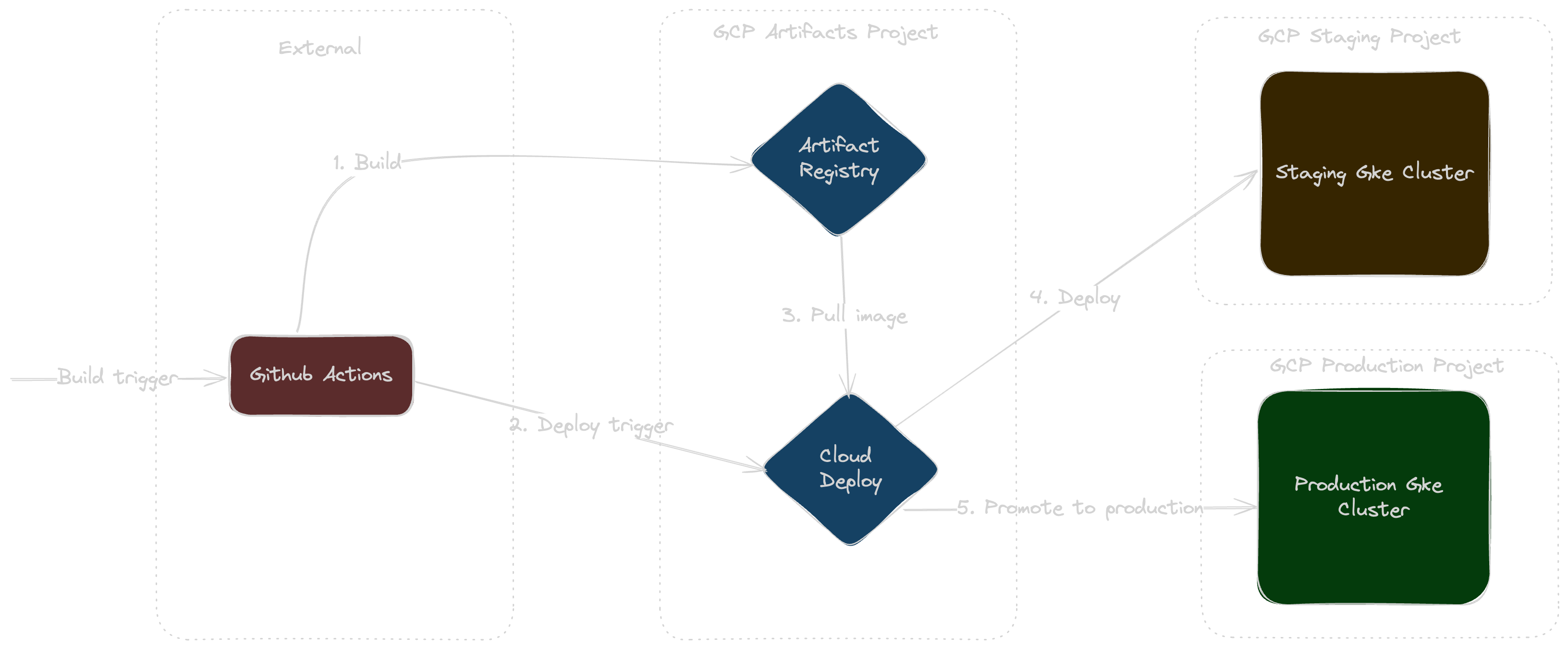
- GitHub Actions for Build - GitHub Actions is used as the build service, which verifies and creates a workload artifact from source, and pushes it to Google Artifact Registry.
- Google Cloud Deploy for Deployment - The deployment step is handled by Google Cloud Deploy, which is triggered right after the build process completes. This step concludes the operations of the build service.
- Automated Staging Deployment - The deployment service automatically progresses the deployment of the built artifact to the staging environment.
- Environment Management and Rollbacks - The deployment service is equipped to handle environment promotions and execute rollbacks whenever necessary.
Putting together this solution on GCP introduced varying levels of complexities, particularly due to requirements for cross-project communication and access limitations inherent in private GKE clusters. A forthcoming article will delve deeper into how these challenges were addressed, offering a more comprehensive insight into the CICD solution's intricacies (stay tuned for updates!).
I hope this article provides an insightful overview of key architectural considerations that you may want to consider for your own GKE cluster setup. While it provides a comprehensive high level overview, a successful implementation demands a deeper dive into each aspect that has been discussed.
An actual end-to-end GKE implementation involves a multifaceted array of components encompassing access control, source control, environment management, Kubernetes manifest file management, CICD integration, network management, resource utilisation, scalability configurations, optimisations and monitoring.
Exploring and mastering these aspects will be instrumental in crafting a robust and optimised GKE environment.